Introduction
Artificial Intelligence (AI) is rapidly penetrating every aspect of society. From planning which delivery route for drivers to take, ruling over what advertisements for target audiences to see, to determine how candidates’ applications to the dream job are screened, people may not even realise that many decisions are much more dependent on algorithms and managing the content by AI than other traditional processes (O’Neil, 2018).
Although this technology has undoubtedly brought convenience to us and has affected access to information, exchange of ideas, and more, a growing number of people concern that the replication and exacerbation of human errors due to the absence of adequate oversight and checks and balances for algorithms (Noble, 2018). For example, since this technology always operates in a corporate black box (Pasquale, 2015), it’s challenging for us to figure out how a certain AI or algorithm is designed, what data is used to build it, and how it is developed or operated.
On November 1, 2019, according to BBC, Steve Wozniak, the co-founder of Apple, said that the algorithms employed to determine limits of Apple Card were intrinsically prejudiced towards women. Apple Card allows tech entrepreneur David Heinemeier Hansen 20 times the credit limit of his wife, despite the fact that his wife has a higher credit score. (BBC, 2019). In addition to gender discrimination, AI perpetuates social biases in race, age, and sexual orientation (Just & Latzer, 2017). In this blog, I will explore how prejudice gets into AI.
Typical Types of Algorithmic Biases
Insufficient Inclusivity
Since datasets of demographic data do not contain various skin features, face recognition technology will lead to different tolerances for different racial groups. For example, face detection and classification algorithms are used by U.S. law enforcement to monitor and prevent crime. In The Perpetual Lineup, Garvie (2016) and his colleagues conducted a year-long study of 100 police departments that showed that African Americans were more likely than other ethnic groups to be searched by law police and subjected to face recognition searches (Garvie et al., 2016). According to related research, the accuracy of face recognition technologies utilised by US law enforcement is poorer for women, black people, and those between the age group of 18 and 30 (Klare et al., 2012). As a result, false positives and unjustified searches put civil liberties at risk.
The AI facial recognition solution has also faced strong criticism for the “Gender Shade” project which stemmed from a stumbling discovery by Ghanaian scientist Joy Buolamwini (2018). Buolamwini discovered that unless she wore a white mask, face recognition software couldn’t detect her presence. The Gender Shades research was initiated by Buolamwini and Gebru (2018), who discovered that IBM, Microsoft, and Megvii Face++ all exhibit differing degrees of “discrimination” against women and dark-skin people. Females, blacks, and subjects aged 18 to 30 have higher error rates than other groups, with a maximum gap of 34.3 per cent (Buolamwini, 2018). That is, the recognition accuracy of females and persons of dark skin tones is much lower than that of males and those of light skin.
Injustice in Predictions and Decision-making
Without human intervention, AI will also reproduce real-world discriminations in the process of predictions and decision-making. For example, in the hiring process, the extensive use of predictive technology can help promote job recruiting, inform job seekers about potentially attractive positions, and present potential candidates to recruiters for proactive outreach. Algorithmic advertising, which enables employers to use hiring budgets more effectively, will make very superficial predictions: they predict who is most likely to respond to these job postings instead of predicting who will succeed in the job positions.
Consequently, even though employers don’t intend to discriminate against particular groups, the predictions may result in employment advertisements that reinforce gender and racial prejudices. Miranda Bogen (2019) and colleagues from Northeastern University and the University of Southern California discovered that broadly targeted advertising for grocery cashier openings on Facebook were seen to 85% of women, whereas taxi firm opportunities were displayed to roughly 75% of black audiences. This scenario is a typical algorithmic bias case that not only reproduces real-life occupational prejudices against women and African Americans while affecting their choice of future career options, further deepening and perpetuating stereotypes about these minorities and such occupations. Additionally, job advertisements are only recommended to targeted audiences, so other people who want to find jobs cannot know this recruitment information. As a legal scholar, Pauline Kim (Bogen, 2019) states, “not informing people of a job opportunity is a highly effective barrier” to job seekers.
Moreover, some AI-driven systems are designed to concern the preferences of recruiters and use these predictions to screen matching applicants. ZipRecruiter’s recommendation system, for example, if the algorithm learns that recruiters are more frequent and likely to interact with white men, it tends to find candidates with those traits and replicate the pattern.
Displays of Algorithmic Bias
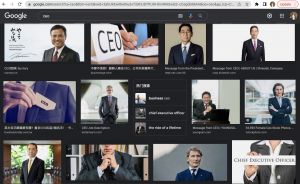
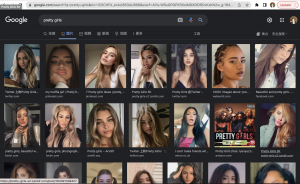
When I search “CEO” on Google, I see a barrage of white males on the first webpage while only one female image appears. Since changing the keyword to “pretty girl”, almost all the pictures shown are thin, long hair, and white females who are traditionally signified as emphasised femininity. The search results reflect the simple aesthetic standard instead of adapting to aesthetic multiformity.
Microsoft’s Robot Tay was taken down barely one day after it was launched on Twitter. Tay was affected by user behaviours and emerged racial discrimination and extremist speech. The displays of bias start with learning in user interactions and are once again overtly presented to more audiences by AI products, creating a chain of bias cycles.
Widespread challenges
Developers and businesses now acknowledge that algorithmic biases are pervasive everywhere (Toesland, 2022). According to Gartner, this technology consulting company indicated that approximately through 2022, 85 per cent of AI assignments will create false results because of bias in data, algorithms, or the managing teams (Gartner, 2018). According to Gartner (2018), most of their clients were unprepared to apply AI owing to a lack of internal data science capabilities, with 53% of these businesses rating their capacity to mine and exploit data as the lowest level. Based on a privacy and ethics expert, Ivana Bartoletti, existing inequalities can be greatly exacerbated by AI, and we need to pay more attention to how to fight AI bias (Toesland, 2022). In her book, The Man-Made Revolution: On Power, Politics, and Artificial Intelligence, Bartoletti (2020) claims,
“we have internalised the idea that there is nothing more objective, neutral,
informative and more efficient than data. This is misleading. When an algorithm is fed data a decision has already been made. Someone has already decided that some data should be chosen and other data should not. And if data is, in reality, people then some of us are being selected while others are being silenced”.
According to the statement, the largest difficulty for organisations is figuring out how widespread prejudices are developed and working to avoid these biases from being fed into AI systems.
Where are Algorithmic Biases From?
Datasets: Soil of Bias
Algorithms do not discriminate against particular groups by nature, and engineers seldom introduce biases to algorithms intentionally. Where does bias originate? This question is strongly connected to machine learning, which is the fundamental mechanism of artificial intelligence.
The following steps can be used to summarise the machine learning process. Data set generation, target formulation and feature selection, and data annotation are the three key phases that lead to algorithmic bias.
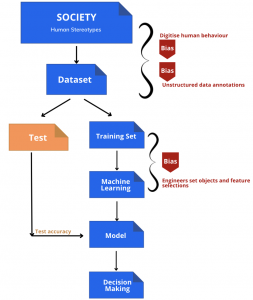
Machine learning is built on the foundation of data sets. If the data sets aren’t representative, they won’t be able to honestly reflect reality, and algorithm conclusions will be biased. Matching bias is a frequent expression of this phenomenon. Data sets tend to be biased towards more “mainstream” and accessible groups due to the ease of data collecting, resulting in unequal distribution at the racial and gender levels.
When tested on Labelled Faces in the Wild, one of the most well-known datasets for face recognition, Facebook’s facial recognition algorithm was found to be 97% accurate. When the researchers examined the so-called gold-standard dataset, they discovered that about 77% of it was male and more than 80% was white. This research suggests that algorithms trained on small datasets may struggle to recognize specific groupings. Women and African Americans may be mislabelled by Facebook’s picture identification.
In addition, when the original datasets have existing social prejudice, the algorithm will also learn the prejudice relationship. For example, Amazon found that its hiring system algorithm used raw data was collected from past employees (Dastin, 2018). Before, Amazon has hired more men. Based on Dastin (2018), algorithms have learnt this feature of the dataset, making it simpler to exclude female job applications.
Engineer: Rule Maker
Improper datasets would contribute to biases from the outset, such as the intent to identify criminals by their faces. The selection of data features can also lead to a typical biased scenario. Data labels are a set of factors that aid in the achievement of an algorithm’s objectives. An algorithm, like a sniffer hound, can only discover its objective with better precision if an engineer tells it what it smells like. As a result, engineers will place labels in the data set to specify what material will be learnt by the algorithm and what type of model will be generated.
Engineers may identify algorithms like “age,” “gender,” and “education level” in Amazon’s recruitment system. As a consequence, when the algorithm learns from previous hiring choices, it recognises this specific combination of characteristics and creates models around it. When engineers think about “gender” as a factor, it’s clear that it has an impact on how algorithms respond to data.
Data labelling: Unintentional Judgment
For some unstructured data sets (such as large amounts of descriptive text, pictures, videos, etc.), algorithms cannot directly analyse them. At this time, it is necessary to manually label the data to extract structured dimensions for training algorithms. When labellers are confronted with a question about whether an image depicts a “cat” or a “dog,” the worst consequence is a false answer; nevertheless, when confronted with a “beautiful or ugly” inquiry, prejudice emerges. Labellers, as data processors, must make subjective value judgements, which can lead to bias. They determine what a ‘failure’ or a ‘criminal’ looks like, even though we don’t know if they have prejudices. Trevor Paglen is one of the ImageNet Roulette project’s creators. It attempts to demonstrate how views, prejudices, and even offensive impressions may affect AI by being the world’s largest picture recognition database. As Paglen (BCNM, 2019) said, “The way we classify images is a product of our worldview,” he said. “Any kind of classification system is always going to reflect the values of the person doing the classifying.”
Many technology businesses have outsourced their huge data for labelling, and manual labelling services have become a common business model. As a result, algorithmic bias is disseminated and reinforced through a “legitimisation” and “invisibility” process.
Conclusion
Due to the extensive application of AI technology and the black-box principle (Pasquale, 2015), algorithmic bias has long been a hidden but ubiquitous social threat. Since AI decision-making has relied on learning human preferences and outcomes, algorithmic biases have been rooted in social traditions, and machines have never independently created biases. From incomplete sets of information in data sources to biased feature selection to the subjectivity introduced by manual labelling, prejudice acquires a certain “concealment” and “legitimacy” to continuously practise and amplify.
References
All the ways hiring algorithms can introduce bias. Harvard Business Review. (2021, August
30). Retrieved April 5, 2022, from https://hbr.org/2019/05/all-the-ways-hiring-
algorithms-can-introduce-bias
Bartoletti, I. (2020). An artificial revolution on power, politics and ai. The Indigo Press.
Buolamwini , J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in … http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf. Retrieved April 2, 2022, from http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf
Gartner says nearly half of cios are planning to deploy artificial intelligence. Gartner. (n.d.). Retrieved April 5, 2022, from https://www.gartner.com/en/newsroom/press-releases/2018- 02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
Garvie, C. (2016). The perpetual line-up: Unregulated Police Face Recognition in America. Georgetown Law, Center on Privacy & Technology.
Just, N., & Latzer, M. (2017). Governance by algorithms: Reality construction by algorithmic selection on the internet. Media, Culture & Society, 39(2), 238–258. https://doi.org/10.1177/0163443716643157
Kim, P., & Scott, S. (2018, August 3). Discrimination in online employment recruiting. SSRN. Retrieved April 5, 2022, from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3214898
Klare, B. F., Burge, M. J., Klontz, J. C., Vorder Bruegge, R. W., & Jain, A. K. (2012). Face recognition performance: Role of Demographic Information. IEEE Transactions on Information Forensics and Security, 7(6), 1789–1801. https://doi.org/10.1109/tifs.2012.2214212
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York University Press.
O’Neil, C. (2018). Weapons of math destruction: How big data increases inequality and threatens democracy. Penguin Books.
Pasquale, F. (2015). The Black Box Society: The Secret Algorithms that control money and information. Harvard University Press.
Thomson Reuters. (2018, October 10). Amazon scraps secret AI recruiting tool that showed bias against women. Reuters. Retrieved April 1, 2022, from https://www.reuters.com/article/us- amazon-com-jobs-automation-insight-idUSKCN1MK08G
Toesland, F. (2022, March 21). How can we overcome bias in algorithms? Techerati. Retrieved April 1, 2022, from https://www.techerati.com/features-hub/opinions/how-can-we-overcome-bias-in-algorithms/
Trevor Paglen’s ImageNet Roulette. Trevor Paglen’s ImageNet Roulette – News/Research – Berkeley Center for New Media. (2019, December 24). Retrieved April 5, 2022, from http://bcnm.berkeley.edu/news-research/3493/trevor-paglen-s-imagenet-roulette